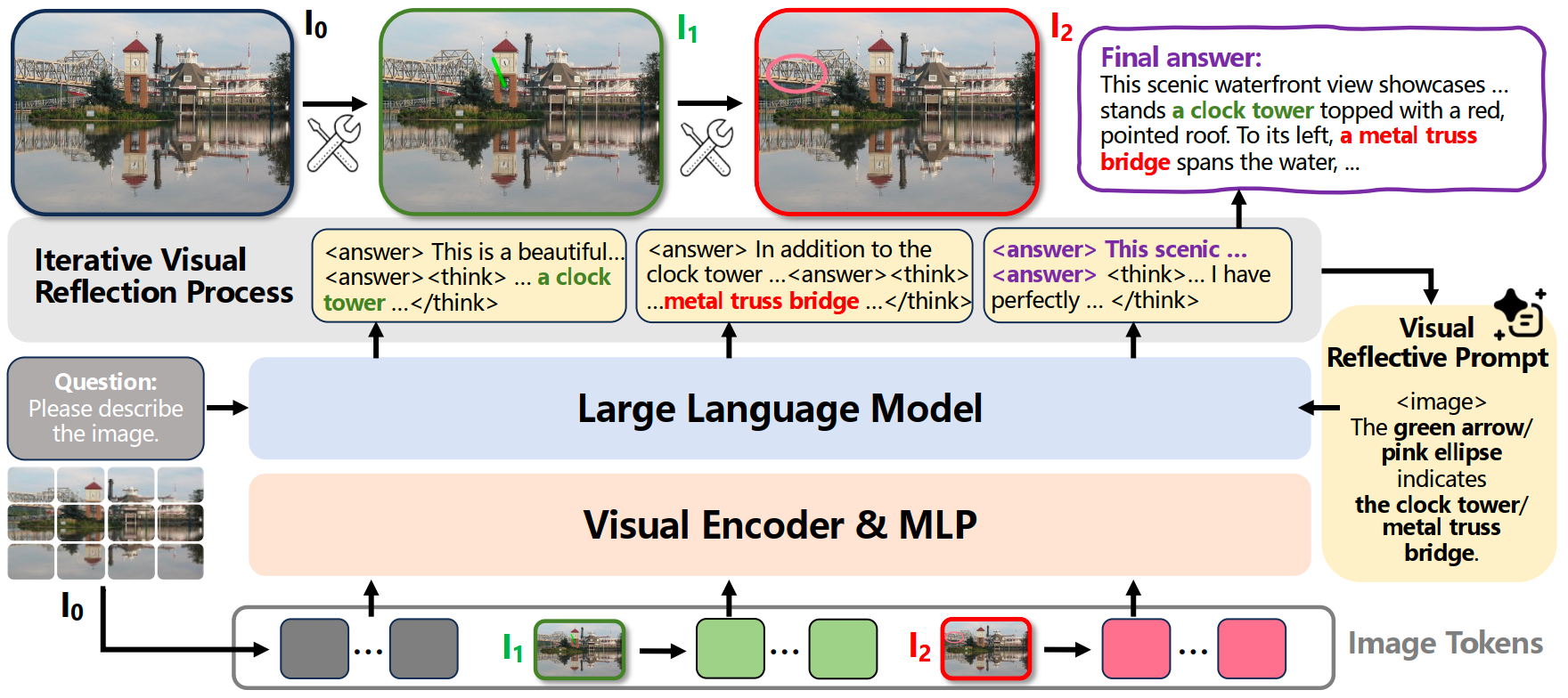
Self-reflection has become a key mechanism for improving reasoning in Vision-Language Models (VLMs), yet this corrective mechanism often fails when resolving complex fine-grained regional ambiguities. This performance degradation stems from the issue of modality disconnect in self-reflection: most existing models execute self-reflection either within textual or latent space, lacking a mechanism to explicitly align textual reasoning with visual evidence.
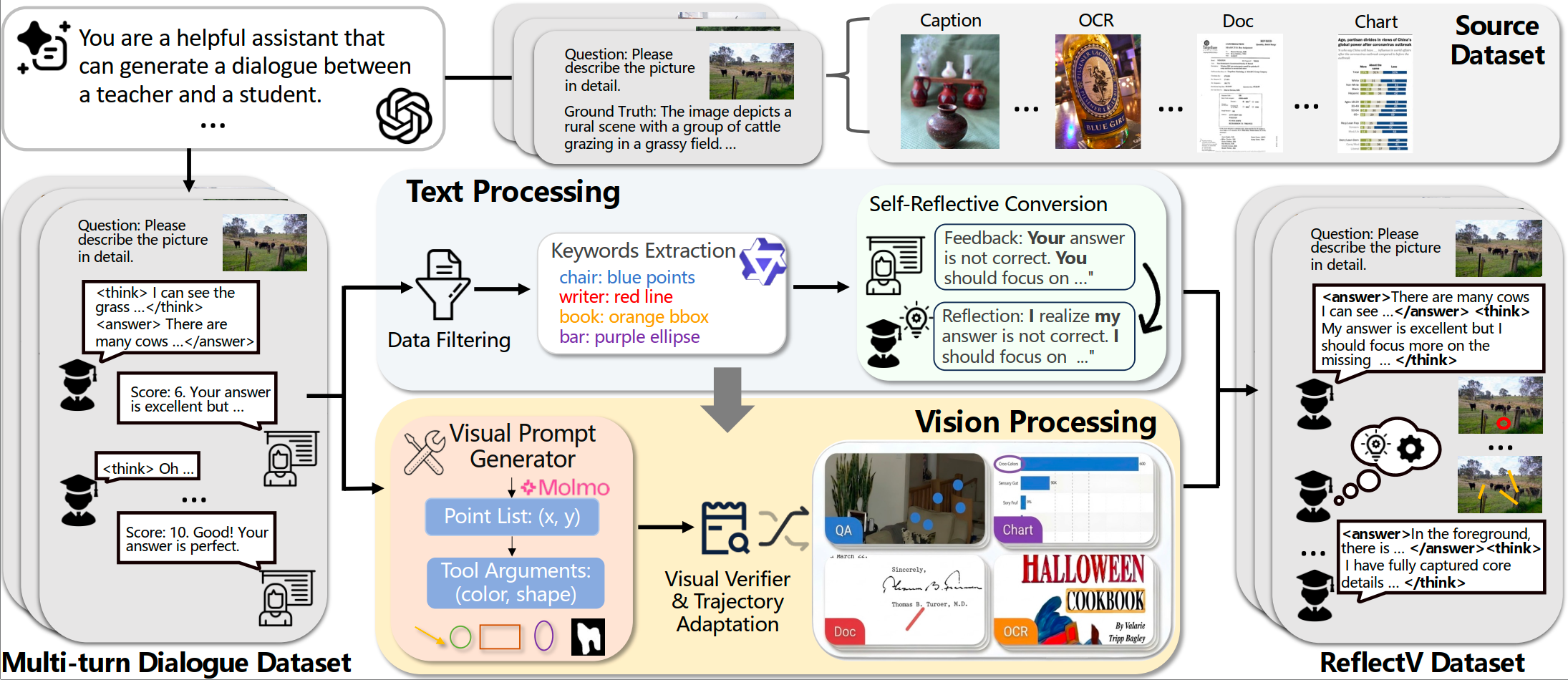
In this paper, we propose MIRROR, a closed-loop visual reflection framework comprising four steps: initial response generation, error identification, region-based visual verification, and revision. In this cycle, the model first generates an initial response, identifies uncertain logical assertions that require visual verification, then grounds them in relevant image regions, and finally revises based on the visual evidence. We construct a multi-turn visual reflection dataset ReflectV, which empowers the model with such reflective capability.
Extensive experiments across 12 diverse multimodal benchmarks show that MIRROR achieves an average absolute improvement of 7.2 percentage points over the base model, with particularly strong gains in hallucination mitigation (+13.36 on HallusionBench) and general reasoning (+10.10 on MM-Vet), demonstrating the advantage of transforming self-reflection from open-loop textual revision into closed-loop, visually grounded verification.